Vertex Technologies LLC
Leading AI solutions provider transforming businesses through innovation.
Leading AI solutions provider transforming businesses through innovation.
The Data Extraction Project is a powerful multimodal AI solution designed to extract structured data from unstructured image and text inputs. By integrating OpenAI GPT-4o’s advanced vision and language understanding capabilities, the system handles complex document formats such as ID cards, invoices, and handwritten checks. Built on Streamlit, it allows users to interactively upload images, receive instant extraction results, and handle multilingual content seamlessly.
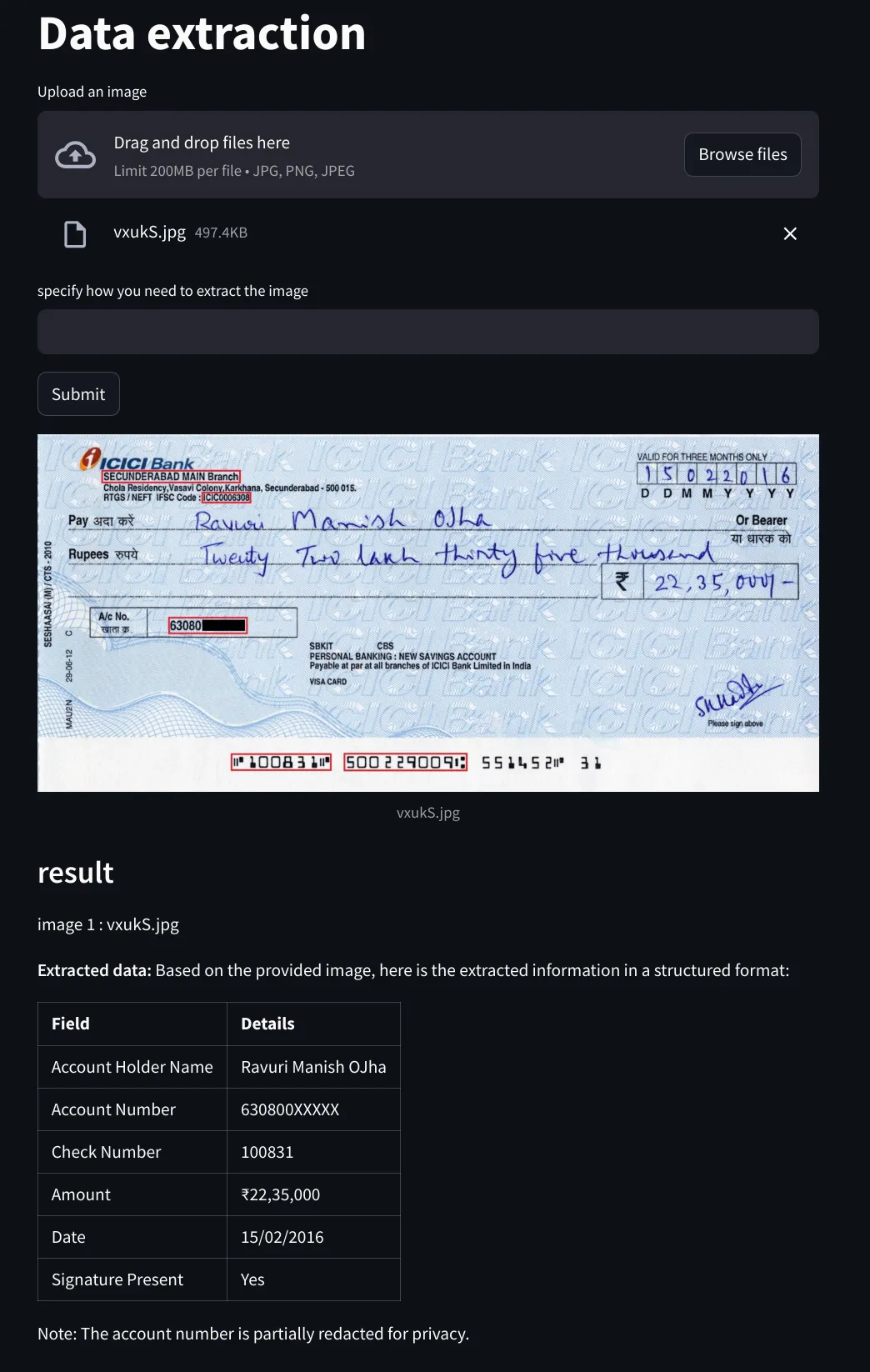
Key challenges included ensuring reliable extraction accuracy across diverse document types, dealing with handwritten and low-resolution inputs, and maintaining performance for multilingual content. Additionally, enabling a smooth user experience in the frontend while handling real-time model inference required careful API design and interface responsiveness.
The solution leveraged OpenAI GPT-4o’s multimodal input processing capabilities for both image and text understanding. Azure-hosted GPT-4 APIs ensured scalability and fast response times. Streamlit was used to build a clean, accessible frontend that enabled real-time interaction. Preprocessing pipelines and structured output formatting improved extraction accuracy and clarity.
The system successfully automated and simplified data extraction from a wide range of real-world documents. It reduced manual effort in bookkeeping, ID verification, and financial workflows while supporting multilingual and handwritten formats. The project demonstrated robust performance in diverse scenarios and served as a scalable base for future document processing solutions.
