Vertex Technologies LLC
Leading AI solutions provider transforming businesses through innovation.
Leading AI solutions provider transforming businesses through innovation.
This project focuses on scraping rubber product data from a specific website, including details about model names, makes, dimensions, and other specifications. The extracted data is stored in CSV format for analysis and reporting.
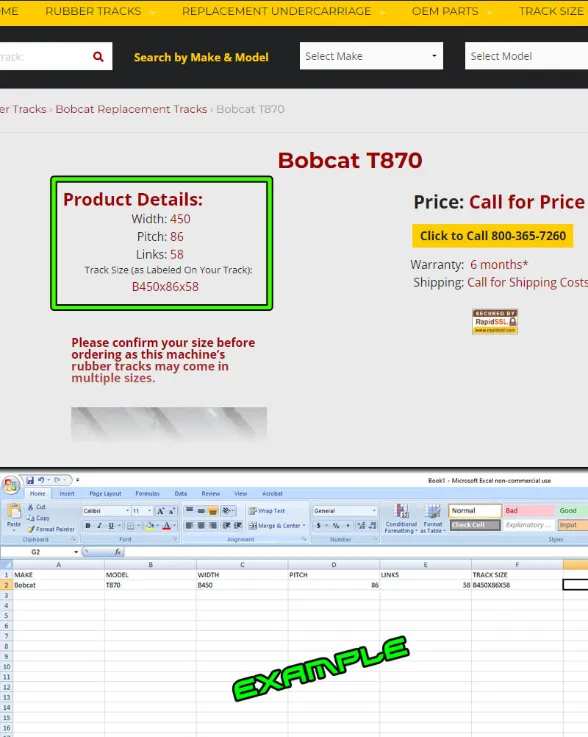
The challenge involved navigating multiple links to extract information from all product pages. Additionally, maintaining accurate data extraction from various product formats and dimensions posed challenges.
BeautifulSoup was used to scrape the required data from multiple pages. The data was then saved in CSV format, making it easily accessible for analysis and reporting.
The system automated the extraction of rubber product data, saving time and effort for the client. The CSV files produced provided a structured format for ongoing analysis.
